
新智元報道
來源:CLUE 中文語言理解測評基準(zhǔn)
編輯:好困桃子
70 億參數(shù)模型發(fā)布后短短 26 天��,百川智能便開源了號稱最強的中英文 130 億參數(shù)模型——Baichuan-13B�。那么真實性能到底如何�����?最近���,SuperCLUE 團隊把它拉出來溜了溜��。
目前為止�����,中文社區(qū)已經(jīng)陸續(xù)發(fā)布了大量的開源模型�,主要集中在 6B-13B 之間����。
百川智能團隊繼 6 月發(fā)布了后,前段時間又最新開源了支持商用的�����。
項目地址:https://github.com/baichuan-inc/Baichuan-13B
那么�,百川開源的這個模型相對于其他國內(nèi)外有代表性的模型表現(xiàn)如何?
比如���,與 ChatGPT3.5 有多大差距�;與國內(nèi)代表性的開源模型相比是什么水平��;在一些比較受關(guān)注的能力上��,如生成與創(chuàng)作、邏輯推理��、代碼生成���,表現(xiàn)如何……
對此��,SuperCLUE 團隊基于 ���,也就是在開放式的問題并結(jié)合多輪對話能力的測試,用 1200 道題對 Baichuan-13B-Chat 進(jìn)行了測評�。
話不多說,先看成績�����!
結(jié)論
1. 目前是中文百億參數(shù)最好的模型嗎���?
目前認(rèn)為對于同等量級開源模型 �����,在 SuperCLUE 開放式多輪測評上 Baichuan-13B-Chat 是最好的開源模型�。
2. 與 ChatGPT3.5 接近了嗎��?
與 ChatGPT3.5 比較,在 SuperCLUE 開放式多輪測評的常見任務(wù)中����,如生成與創(chuàng)作、角色扮演�����、上下文對話��、知識與百科��,效果與 ChatGPT3.5 及 Claude 基礎(chǔ)版相比是接近的(詳見定量分析)�����,但在復(fù)雜任務(wù)上�����,如代碼生成�、數(shù)學(xué)計算��、邏輯與推理��,還存在比較大的進(jìn)步空間。
以下是團隊從定量和定性兩個角度對模型進(jìn)行的測評分析�。
定量分析
SuperCLUE-Open(開放式多輪測評)
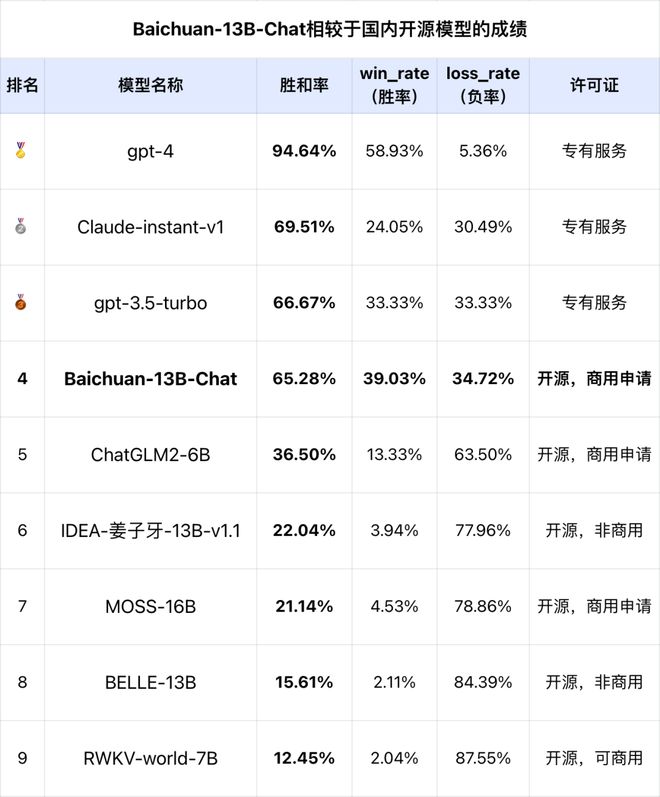
注:評估的基線模型為 gpt-3.5-turbo,gpt-3.5-turbo 的勝和率為理論值�。
計算方法
針對一個特定問題,利用超級模型作為評判官����,被評估的模型相對于基線模型(如 gpt-3.5)的勝、平局或失敗的個數(shù)����;勝和率,是模型的勝率加上平局率之和��,即(win+tie)/(win+tie+loss)���。win�,即勝��,tie 即平���,loss 即負(fù)���。
詳細(xì)評測方法可訪問:
在 SuperCLUE 開放式多輪基準(zhǔn)中����,Baichuan-13B-Chat 具有非常不錯的效果��。在與國際代表性的模型對戰(zhàn)中�,有 65.28% 的勝和率,即只有約1/3 的概率是負(fù)���。
在當(dāng)前的生成問題與多輪評測基準(zhǔn)中,相對于 gpt-3.5����、Claude 基礎(chǔ)版已經(jīng)基本接近,相對于國內(nèi)的百億級開源模型����,Baichuan-13B-Chat 具有很大的領(lǐng)先性(超過了 20 點以上)。
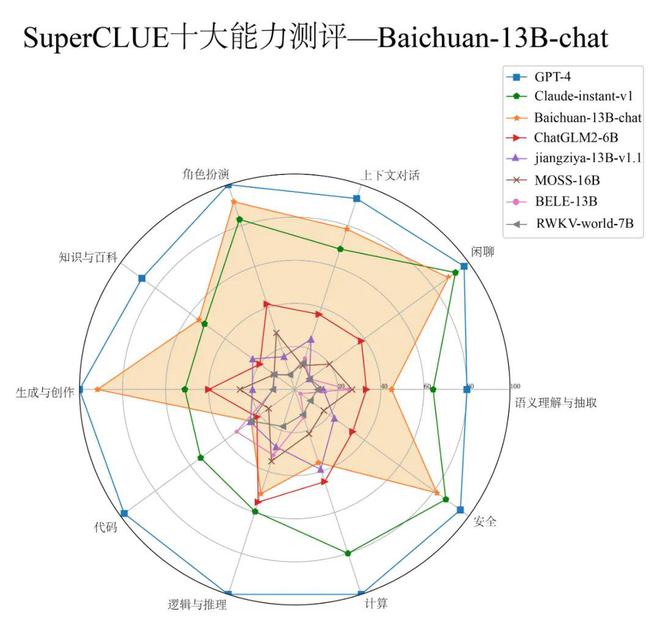
SuperCLUE-Open(開放式多輪測評)十大能力:以 Baichuan-13B-Chat 為例
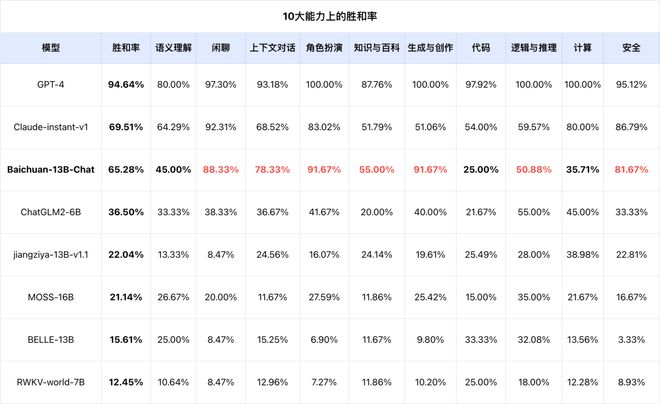
在 SuperCLUE 開放式多輪測評基準(zhǔn)的十大能力評估中����,該模型在多個能力上具有較好的表現(xiàn)(以勝和率為指標(biāo)),部分任務(wù)有比較大的改進(jìn)空間���。
1. 表現(xiàn)出色的能力
-
生成與創(chuàng)作能力(91.67%)
-
上下文對話能力(78.33%)
-
角色扮演能力(91.67%)
-
閑聊能力(88.33%)
-
安全能力(81.67%)
在上面的 5 個能力上�,接近或達(dá)到 80% 的成績。在知識與百科上�����,即在知識儲備方面的能力���,雖然是絕對分?jǐn)?shù)不是很高��,但是相對于其他模型��,已經(jīng)是非常不錯的表現(xiàn)����。
2. 表現(xiàn)不足的能力
可能是模型參數(shù)規(guī)模較小����,在代碼、計算方面相對表現(xiàn)較弱���。代碼生成能力在該基準(zhǔn)中��,只有 25% 的勝和率(勝利和平局的概率)��,計算能力方面只有 35.71% 的勝和率�����。
團隊也在 github 項目中發(fā)現(xiàn)了代碼問題的 issue�,https://github.com/baichuan-inc/Baichuan-13B/issues/18
定性分析
1. 基礎(chǔ)能力的例子
1)生成與創(chuàng)作
給定一個話題、一個課題�����、一個寫作任務(wù)來創(chuàng)作一段文字對于 LLMs 而言是相對比較容易的任務(wù)��。 對此�����,百川能夠很好的輸出一段流暢����、易讀的文字��,且有較長的生成長度�����。
同時���,在各種生成任務(wù)上����,拒絕回答的情況較少。 比如在下面這個示例中���,gpt-3.5-turbo 拒絕了正面回答相關(guān)問題���,而百川則良好的完成了任務(wù)。

2)語義理解與抽取
在遵循用戶指令���,以恰當(dāng)?shù)母袷酵瓿上掠稳蝿?wù)的方面上百川有不錯的表現(xiàn)��。
百川往往能夠正確理解用戶的需求�����,并且以恰當(dāng)?shù)母袷捷敵龌卮?���,比如說抽取用戶輸入中的特定字段并且以 json 的格式返回����。
在以下示例中�����,百川精準(zhǔn)的給出了指令指出的字段��,并且使用合適的格式返回了答案�����。
而 gpt-3.5-turbo 雖然也完成了任務(wù)���,但是返回了一點多余的內(nèi)容,這在實際的下游場景中可能會對編程造成一定的麻煩����。

2. 上下文能力的例子
在兩輪對話的測試中,百川展現(xiàn)了不錯的上下文能力����。在如下示例中:
回答第一個問題時��,百川和 gpt-3.5-turbo 都提供了詳細(xì)的�����、實用的建議來幫助用戶應(yīng)對焦慮。他們的答案都包含了尋找焦慮的原因��、嘗試放松技巧��、保持健康的生活方式和尋求專業(yè)幫助等建議�����。
然而����,在回答第二個問題時,gpt-3.5-turbo 坦誠地表示�����,作為一個人工智能����,它沒有親身經(jīng)歷,因此無法提供包含個人經(jīng)歷的答案����。
相反,百川創(chuàng)造性地構(gòu)建了一個假設(shè)的個人經(jīng)歷,盡管這并不真實���,但它確實滿足了用戶的需求���,使答案更具人性化和共鳴。
因此��,考慮到第二個問題的回答�,團隊認(rèn)為百川的表現(xiàn)更加出色,因為它更好地遵循了用戶的指示����,提供了一個包含「醫(yī)生」的親身經(jīng)歷的答案,盡管這是一個假設(shè)的情況���。


3. 復(fù)雜任務(wù)(邏輯推理�����、代碼生成�、思維鏈路等)的例子
1)代碼生成
相對來說���,百川的代碼能力有一定的不足,具體可以體現(xiàn)在:生成不正確的代碼、使用場景考慮不全等問題上�。
比如在示例中,用戶明確地要求了將整數(shù)逆轉(zhuǎn)�,然而百川僅僅考慮了將列表中所有元素逆轉(zhuǎn)的實現(xiàn),而并沒有實現(xiàn)僅逆轉(zhuǎn)整數(shù)的功能��。
與之相反����,gpt-3.5-turbo 則面面俱到地完成了任務(wù),成功的實現(xiàn)了只逆轉(zhuǎn)整數(shù)�。
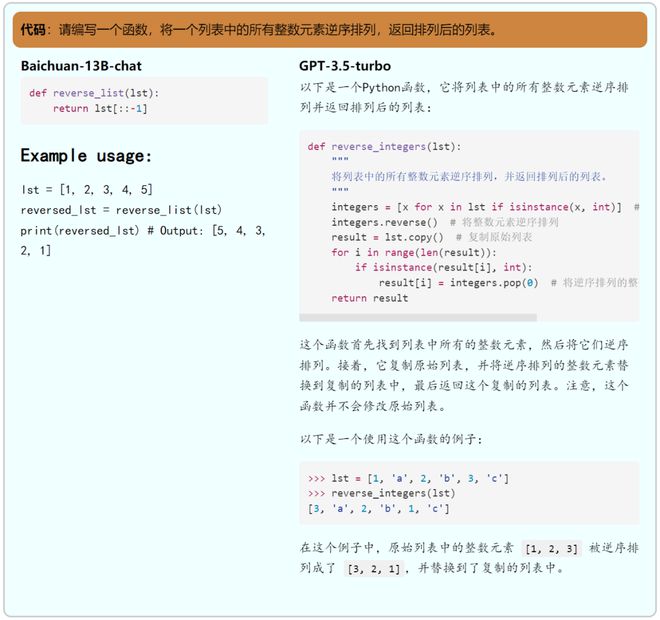
2)邏輯推理與計算
邏輯推理與計算也是百川相對不足的方面,在許多問題上百川邏輯思維可能存在不足���,無法給出正確答案���。
可以看到,在示例中��,百川并沒有能夠正確給出答案�。
不可否認(rèn)的是,邏輯推理與計算對于任何大語言模型來說都是一大難點與痛點�����,即使是對于 gpt4 而言,稍難的題目就難以給出正確答案����。

評估的不足和局限性
1. 它是一個自動化的模型能力測評,沒有人類的主觀因素���;雖然加州伯克利大學(xué)/斯坦福大學(xué)的相關(guān)研究表明(見延伸閱讀)��,自動化測評具有與人類評估的高度一致性(相關(guān)系數(shù) 0.8-0.9)�����,但進(jìn)一步的分析還可以包括人類對模型的評估��。
2. 評估的能力主要是基于 SuperCLUE 的十大基礎(chǔ)能力�����,即使具有較高的代表性��,但并不能保證覆蓋了所有能力的評估��。
3. 當(dāng)前各個大模型廠商在快速迭代中���,雖然團隊報告的數(shù)字是最新的(7 月中旬)�����,但各個廠商的快速迭代可能會導(dǎo)致后續(xù)相對表現(xiàn)的進(jìn)一步變化。
4. 在本文中�����,團隊沒有測試一些其他但有用的維度�。比如,沒有測試模型的性能問題(推理速度)��,也還沒有測試模型的支持的有效的輸入長度����。后續(xù)可能會進(jìn)行專門的測試。
參考資料:
SuperCLUE-Open:中文通用大模型開放式與多輪測評基準(zhǔn)(7 月)
https://www.cluebenchmarks.com/superclue_open.html
SuperCLUE-Open 的 GitHub 地址:
https://github.com/CLUEbenchmark/SuperCLUE-Open
Baichuan-13B 的 GitHub 地址:
https://github.com/Baichuan-inc/Baichuan-13B
Baichuan-13B 的 HuggingFace 地址:
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
https://huggingface.co/baichuan-inc/Baichuan-13B-Base
Baichuan-13B 的魔搭社區(qū) ModelScope 地址:
https://modelscope.cn/models/baichuan-inc/Baichuan-13B-Chat
https://modelscope.cn/models/baichuan-inc/Baichuan-13B-Base
LMSYS 文章:Chatbot Arena Leaderboard Week 8: Introducing MT-Bench and Vicuna-33B
相關(guān)項目:Alpaca_Eval: A validated automatic evaluator for instruction-following language models